dREG Documentation
1 Login
The user needs to log in by clicking 'Log in' link at the top-right corner of the page. Having an account provides a number of benefits, and is free and easy.
2 Create a new experiment
Select the dREG application on the Dashboard panel to create a data analysis for your data, as the following screenshot (Figure 2).
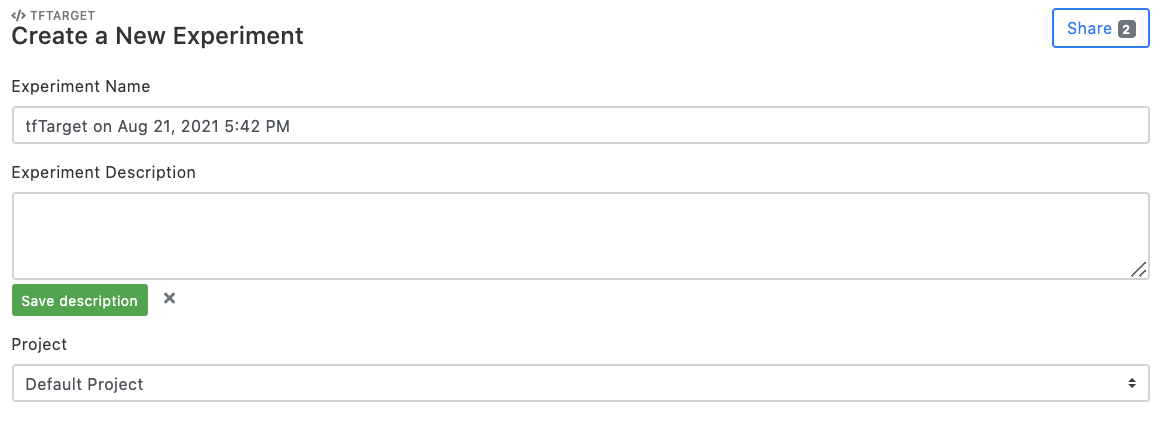
3 Set experiment name
Set "Experiment Name", and click "Add a description" to comment on the experimental setup page (optional). Choose the project that the experiment belongs to. By default, the "Default Project" is created and used.
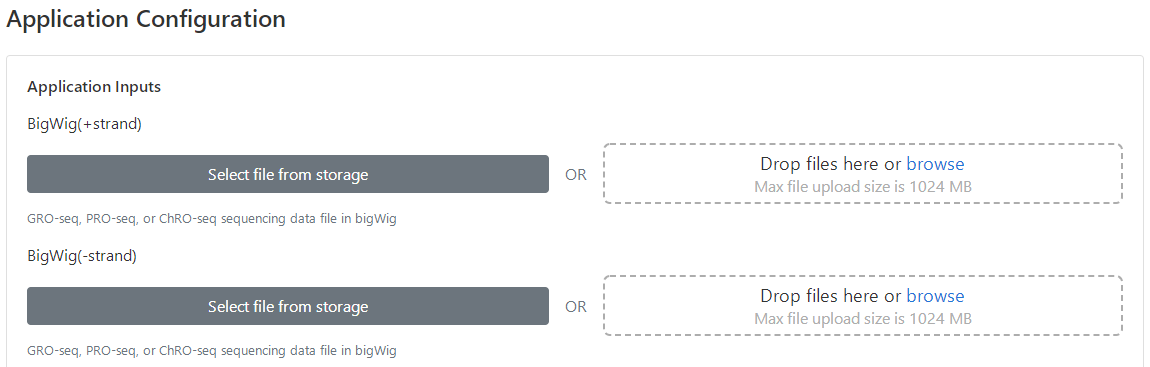
4 Upload bigWig files
There are two ways users may use to upload bigWigs.
(1) Click "Select files from storage" to choose existing files submitted for previous tasks, or
(2) click "Drop files here or browse" to upload new files from user's storage. Note that the bigWig files of run-on sequencing are strand-specific, and hence the ordering of bigWig files needs to be matched for plus and minus strands within each condition. Additionally, as dREG uses DESeq2 to model differential transcription and perform hypothesis testing, at least two replicates are required for each condition.
5 Set computing parameters
(1) Specify the prefix of the output files. This can help distinguish results from multiple experiments.

6 Submit the job
Once steps 1-5 are finished, proceed to "Save and launch". Input data and parameters will be submitted to the computing node of the XSEDE cluster via the dREG gateway server. Click the checkbox next to "Receive email notification of experiment status" if needed. dREG peak calling will be automatically performed on bigWigs merged for each condition. Upon launching, users will be directed to the "Experiments" page, shown in Fig. 4. A typical experiment usually finishes within 4 hrs. Users may view the progress by logging in and clicking the "Experiment" button on the left control panel at the dashboard.
7 Check the status
Users may view the progress by logging in and clicking the "Experiments" button on the left control panel at the dashboard. All experiments submitted are listed on this page.
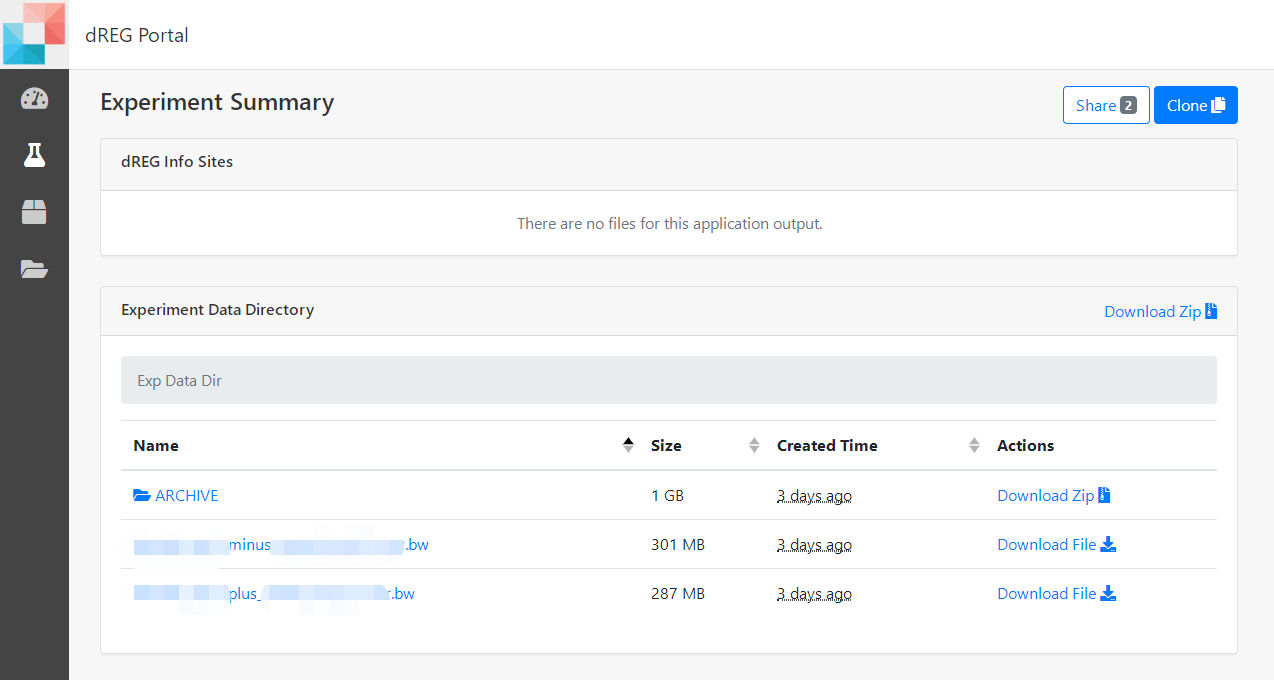
8 Check the results
Once a job is completed, the user can click selected dREG experiment and the website will jump to Experiment Summary page. All parameters used to set up the experiment are listed on this page. The user can also access output files of dREG stored in the ARCHIVE. Just click the ARCHIVE to check any single result file. A compressed file, including input bigWigs file set, two task log files and all result files, is also provided for users. Click Download Zip button to download a compressed file. The downloaded file with the 'tar.gz' extension can be decompressed by the 'tar' command, the file with the 'gz' extension can be decompressed by the 'gunzip' command in Linux.
In Safari, it could be problematic because Safari tries to unzip the compressed results automatically using a non-compatible compress method. Please check this link to disable this feature.
The input to dREG consists of two bigWig files which represent the position of RNA polymerase on the positive and negative strands. The sequence alignment and processing steps to make the input bigWig files are a major factor influencing how accurately dREG predicts TIRs. dREG makes several assumptions about data processing that are critical for success.
Critical elements of a bioinformatics pipeline that is compatible with dREG will include:
- Representing RNA polymerase location using a single base.
PRO-seq measures the location of the RNA polymerase active site, in many cases at nearly single nucleotide resolution. Therefore, it is logical to represent the coordinate of RNA polymerase using the genomic position that best represents the polymerase location, rather than representing the entire read. dREG assumes that each read is represented in the bigWig file by a single base. We have noted poor performance when reads are extended. It is critical that users pass in bigWig files that represent RNA polymerase using a single nucleotide.
- Include a copy of the Pol I transcription unit in the reference genome.
PRO-seq data resolves the location of all four RNA polymerases found in Metazoan cells (Pol I, II, III, and Mt). DNA encoding the Pol I transcription unit is highly repetitive, and is not included in most mammalian reference genomes. Nevertheless, the Pol I transcription unit is a substantial source of reads in a typical PRO-seq experiment (10-30%). Many of these reads will align spuriously to retrotransposed and non-functional copies of the Pol I transcription unit, which can create mapping artifacts. To solve this issue, we include a single copy of the repeating DNA that encodes the Pol I transcription unit in the reference genome used to map reads. We use GenBank ID# U13369.1. Including a copy of this transcription unit provides an alternative place for Pol I reads to map, preventing reads from accumulating in Pol I repeats.
- Trim 3' adapters, but leave the fragments.
Much of the signal for dREG comes from paused RNA polymerase. RNA polymerase pauses 30-60 bp downstream of the transcription start site. Due to this short RNA fragment length, paused reads in most PRO-seq libraries will sequence a substantial amount of adapter. This leads to poor mapping rates in full-length reads. Therefore, it is crucial to remove contaminating 3' adapters so that paused fragments will map to the reference genome properly.
- Data represents unnormalized raw counts.
dREG assumes that data represents the number of individual sequence tags that are located at each genomic position. For this reason, it is critical that input data is not normalized. The dREG server checks to ensure that input data is expressed as integers, and will return an error if this is not the case.
Users can also use scripts generated in the Danko lab to create compatible bigWig files. Options for scripts at different starting points in the analysis are given below:
- Convert raw fastq files into bigWig.
Our pipeline produces bigWig files that are compatible with dREG, and can be found at the following URL: https://github.com/Danko-Lab/proseq_2.0. Our PRO-seq pipeline takes single-end or pair-ended sequencing reads (fastq format) as input. The pipeline automates routine pre-processing and alignment steps, including pre-processing reads to remove the adapter sequences and trim based on base quality, and deduplicate the reads if UMI barcodes are used. Sequencing reads are mapped to a reference genome using BWA. Aligned BAM files are converted into bigWig format in which each read is represented by a single base.
- Convert mapped reads in BAM files into bigWigs.
We provide a tool that converts mapped reads from a BAM file into bigWig files that are compatible with dREG. This tool is available here: https://github.com/Danko-Lab/RunOnBamToBigWig.
Other considerations:
The quality and quantity of the experimental data are major factors in determining how sensitive dREG will be in detecting TREs. We have found that dREG has a reasonable statistical power for discovering TREs with as few as ~40M uniquely mappable reads, and saturates detection of TREs in well-studied ENCODE cell lines with >80M reads. To increase the number of reads available for TRE discovery, we encourage users to merge biological replicates in order to improve statistical power prior to running dREG.
We have found that visualizing aligned data in a genome browser prior (e.g., IGV or UCSC) to downstream analysis is a useful way to catch any data quality or alignment issues.
1) dREG run generates a compressed file including the dREG results as follows:
| File name | Description |
|---|---|
| $PREFIX.dREG.infp.bed.gz | Informative positions with dREG scores predicted by the dREG model. Decompress it with 'gunzip' in Linux. |
| $PREFIX.dREG.peak.full.bed.gz | Significant peaks (FDR < 0.05) with dREG scores, p-values and center positions where the maximum dREG scores are located. Decompress it with 'gunzip' in Linux. |
| $PREFIX.dREG.peak.score.bed.gz | Significant peaks (FDR < 0.05) only with dREG scores. Decompress it with 'gunzip' in Linux. |
| $PREFIX.dREG.peak.prob.bed.gz | Significant peaks (FDR < 0.05) only with p-values. Decompress it with 'gunzip' in Linux. |
| $PREFIX.dREG.raw.peak.bed.gz | All raw peaks generated by dREG peak calling, including dREG scores, uncorrected p-values, center positions where the maximum are located in smoothed curves, center positions where the maximim are lcoated in original curve, centroid. Only available in the Web storage. |
| $PREFIX.tar.gz | Including above 5 files, can be decompressed by 'tar -xvzf' in Linux. |
Informative position: Loci denoted as "informative positions" meet the following criteria: contain more than 3 reads in 100 bp interval on either strand, or more than 1 read in 1Kbp interval on both strands. Informative positions are used to predict the dREG scores for TRE (Transcription Regulatory Element) identification.
dREG score: Training and prediction is done using a Support Vector Regression model where a label of 1 indicates RNA polymerase II initialization or transciption through the informative position. The predicted values from the pre-trained model are called dREG scores. A dREG score close to 1 indicates that a position likely a TRE.
Peak p-value: We test 5 dREG scores around each candidate peak center using the NULL hypothesis that each point within this peak is drawn from the non-TRE distribution. This test estimates the statistical confidence of each candidate dREG peak. In the final result, FDR is applied to do multiple correction and only the peaks with adjusted p-value < 0.05 are reported.
2) In the Web storage folder there are some files required by the WashU genome browser:
| File name | Description |
|---|---|
| $PREFIX.dREG.infp.bw | The bigWig file converted from the bed file of informative positions ($PREFIX.dREG.infp.bed.gz). |
| $PREFIX.dREG.peak.score.bw | The bigWig file converted from the significant peaks (FDR < 0.05) with dREG scores ($PREFIX.dREG.peak.score.bed.gz). |
| $PREFIX.dREG.peak.prob.bw | The bigWig file converted from the significant peaks (FDR < 0.05) with p-values ($PREFIX.dREG.peak.prob.bed.gz). |
| *.bed.gz.tbi | The index files generated from the corresponding bed files. Please ignore them if you download the results. |
3) There are two log files in the Web storage folder:
| File name | Description |
|---|---|
| $PREFIX.dREG.log | Print the summary information after peak calling. If the bigWigs don't meet the requirements of dREG, the warning information will be outputted in this file. |
| slurm-??????.out | The verbose logging output of dREG package. |
dREG Gateway is online service that supports Web-based science through the execution of online computational experiments and the management of data. The items below are trying to answer qustions from the users
Q: How should I prepare bigWig files for use with the dREG gateway?
A: Information about how to prepare files can be found here .
Q: How should I do when I meet the computational failure in the dREG gateway?
A: There are two types of error you may have, we explain how to identify your error and how to handle it here.
Q: Which browser works well with the dREG gateway?
A: We have tested in the Firefox, Google Chrome and Safari so far. For IE (version 10 or 11) and some version of Safari, you maybe have trouble showing sequence data in WashU genome browser. For Safari users, please read next Q&A.
Q: What should the Safari users be aware of?
A: By default, Safari unzips a zip file automatically when you download it. However dREG results are compressed by the 'bgzip' command which is not compatiable with the Safari method. It would be probelmatic when you download dREG results. Please refer to this link to disable this feature in Safari and then download the compressed results from dREG gateway. Secondly, when you click the genome browser link, please use the Left-Click, don't use Right-Click menu and the menu option "open a new tab".
Q: What types of enhancers and promoters can be identified using the dREG gateway?
A: As a general rule of thumb, high-quality datasets provide very similar groups of enhancers and promoters as ChIP-seq for H3K27ac. This suggests that dREG identifies the location of all of the so-called 'active' class of enhancers and promoters.
Q: Will the dREG gateway work with my data type?
A: The dREG gateway will work well with data collected by any run-on and sequencing method, including GRO-seq, PRO-seq, or ChRO-seq. Other methods that map the location of RNA polymerase genome wide using alternative tools (for example, NET-seq) will most likely work well, but are not officially supported.
Q: Will the pre-trained models work using data from my species?
A: Models are currently available only in mammalian organisms. The length and density of genes, which vary considerably between highly divergent species, affects the way that a transcribed promoter or enhancer looks. For this reason, models can only be used in species. We are working to create models in widely-used model organisms, including drosophila and C. elegans.
Q: How deeply do I need to sequence PRO-seq libraries?
A: Sensitivity is reasonable at ~40 million mapped reads and saturates at ~100 million mapped reads. See our analysis here: supplementary figure 3 in dREG paper.
Q: How long do my data and results keep in the dREG gateway?
A: One month.
Q: How to I cite the dREG gateway?
A: Please cite one of our papers if you use dREG results in your publication:
A: Please cite one of our papers if you use dREG results in your publication:
(1) Wang, Z., Chu, T., Choate, L. A., & Danko, C. G. (2019). Identification of regulatory elements from nascent transcription using dREG. Genome research, 29(2), 293-303.
Q: Do I have to create account before using this service?
A: Yes, this system is supported by an NSF funded supercomputing resource known as XSEDE, who regularly needs to report bulk usage statistics to NSF. Nevertheless, data that you provide are completely safe.
Q: How do I know the status of the computational nodes?
A: Since we can't update this web site very often, the gateway status is updated here on the dREG page based on the notifications of the XSEDE community.
Q: Who do I thank for the computing power?
A: This web-based tool is powered by SciGaP and Apache Airavata and the GPU servers are supported by the XSEDE.
Q: I have another question that is not on this FAQ. How can I contact you?
A: Yes, please contact us with any questions! Zhong(zw355 at cornell.edu). Charles(cgd24 at cornell.edu).
